By Laurence Fish, Developer, Autochartist.com
Price data is central to our business in the drawing of the charts and the technical analysis underpinning the pattern recognition used in the charts. The data received is time critical as the technical analysis and chart patterns derived from the data are performed ideally within one minute of receipt of the data.
The candle data received are typically at fifteen-minute intervals and only generated during the exchange open times. This means that computing resources are only required at fifteen-minute intervals for a few minutes (typically less than two minutes) at each scheduled time slot. This makes the serverless solution ideal as we only pay for the processing time used.
The main aim of adopting a serverless approach is to optimize resource utilization thereby reducing costs. A prime candidate was identified as the data feed layer we employ to source candle data from various external third-party feeds.
This article will address the implementation pertaining to the instrument pricing data feeds although there are multiple other instances of serverless architecture being implemented at Autochartist, one prominent example being the automated batch mailing of reports.
We have employed AWS Lambdas for handling data feeds as in this high-level architectural overview:
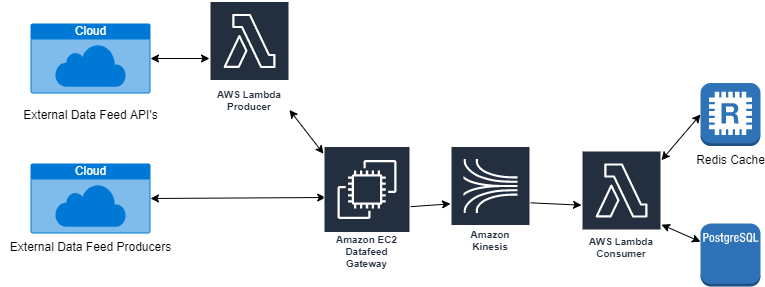
We deploy the lambda handler code as Java 8 .jar files that include all the library dependencies for performing HTTP calls or connecting to external data sources e.g. PostgreSQL, Redis and MongoDB. Recently, AWS has introduced ‘Lambda Layers’ that can be used for storing common library files thereby reducing the size of the deployable jar file significantly (by up to 80%).
The deployment of the executable .jar files is automated using standard Jenkins plugins during the nightly build phase.
We will now trace the typical data flow using the high-level architectural overview above as a guide:
- The Lambda Producer is triggered using AWS Cloudwatch cron schedules. Each data feed has its own cron schedule that sends a simple string value of the data feed name (e.g. “SAXO”) to trigger the producer.
- On receipt of the trigger, the producer executes a call to the external data feed API to retrieve the candle data.
- The producer then sends the candle data to the Data Feed Gateway that, in turn, forwards the data in payloads to AWS Kinesis that performs as the transport layer in the architecture. Note that the Data Feed Gateway provides an API that can be used by third-party producers to upload pricing data.
- The lambda consumer is triggered by each payload on the Kinesis stream. The consumer deserializes the payload data and writes the data to a Redis cache as well as to the T-tables in the PostgreSQL database.
- The Redis cache is used to store all the candles received in order to provide a data store for rolling up the candles into higher intervals e.g. from 15-minute to 30-minute intervals. This reduces the load demand on the PostgreSQL database that might otherwise be used for rolling up the candles.
- The PostgreSQL database stores the T-table data for use by the recognition engines for performing the analysis and pattern recognition.
Good impressions…
Overall, the serverless implementation has been successful, especially in terms of:
- Stability – virtually no downtime during normal operation has been experienced.
- Ease of deployment – AWS lambda interface allows for extremely easy deployment (and reverting) of .jar files.
- Ease of development – new data feed interfaces can be developed relatively quickly (typically in less than a day for RESTful API’s) by adding new service code on the producer handler. The consumer simply requires additional configuration on MongoDB for the new feed.
And now the bad…
The main draw-backs in implementing the server-less architecture on AWS have been:
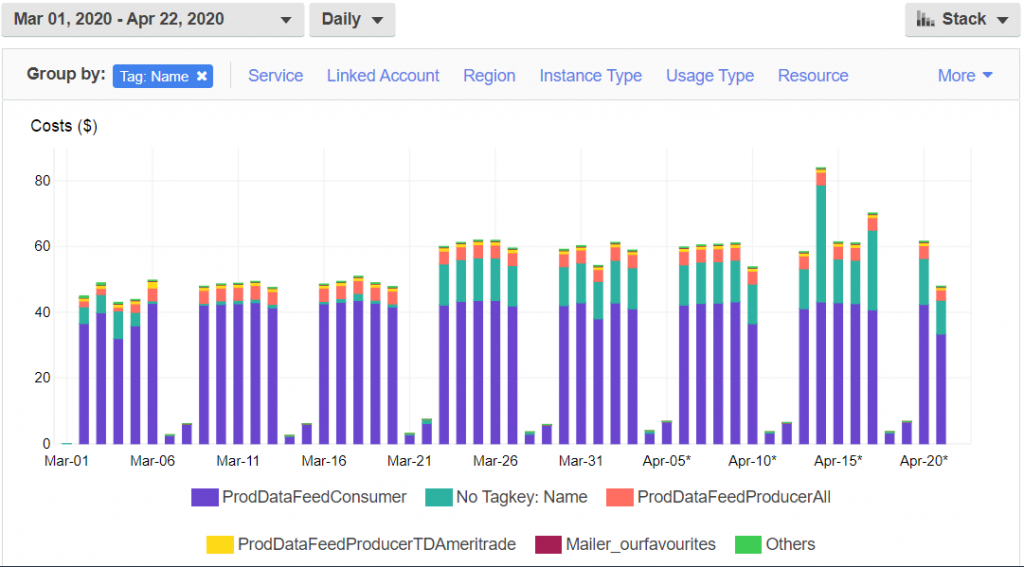
- Technology lock-in and its associated cost – as the AWS lambdas have a set of limited, pre-defined triggers, this creates a situation of technology lock-in, the starkest example being the transport layer where we opted to use AWS Kinesis streaming. Daily costs for Kinesis are about US$23.00 as seen in the cost analysis below:

The transport layer cost is unacceptably high, given the transient, bursty nature of the data being streamed i.e. every 15 minutes for 5 days per week.
We have tried reducing the costs by optimizing the number of shards in each stream while maintaining optimal throughput with minimal latency – it has had a negligible effect on the associated costs.
- Design and Implementation of lambdas – It is a mistake to assume that the transient nature of AWS Lambdas will automatically and magically reduce running costs. Careful resource planning and adherence to microservice design principles and being aware of various pitfalls (discussed below) will definitely pay off.
Looking at the daily costs of the Lambda implementations below clearly shows we’re taking a hit on the ‘ProdDataFeedConsumer’ Lambda at around $30.00 to $35.00 per day. The producer Lambda (‘ProdDataFeedProducerAll’) is typically under $3.00 per day which is pretty acceptable.
As we are processing (at peak) 6445 instruments every 15 minutes, we can calculate the processing cost per instrument/ candle per day:
$35.00 / ((6445 candles) * (4 * 24 hours))
= $ 35.00 / 618 720 candles per day
= $0.0000566 / candle per day
What have we done wrong in terms of the consumer Lambda to incur these high costs?
Here are some areas I’ve identified for improvement as well as solutions:
- Over-provisioning – It is critical to look at the actual resource requirements for the Lambda as assumptions and ‘just provisioning to the max’ and ‘playing it safe’ can be costly. The three critical elements to configure for a Lambda are:
- Number of concurrent executions for the Lambda
- Amount of memory required
- Duration (average) of the invocations
Our original configuration for the consumer Lambda was as follows:
- Total invocations per month =
((215 executions per 15-min interval) * (4 invocations per hour)) * 24hrs * (21.67 working days per month)
= 447 268
Where 215 executions was the average number of executions per 15-minute interval.
- Amount of memory required – we chose the max at 3008 MB.
- Duration – an average duration of the Lambda invocations was around 45 seconds.
This configuration has been the main cause of the high cost of implementation.
A quick calculation using https://dashbird.io/lambda-cost-calculator/ confirms this:

Let’s look at what our actual provisioning requirements should be.
There are two factors we can change:
- Amount of memory required – this should not be more than about 400 MB if we look at the CloudWatch Logs Insights for the Lambda detailing memory usage for each invocation:
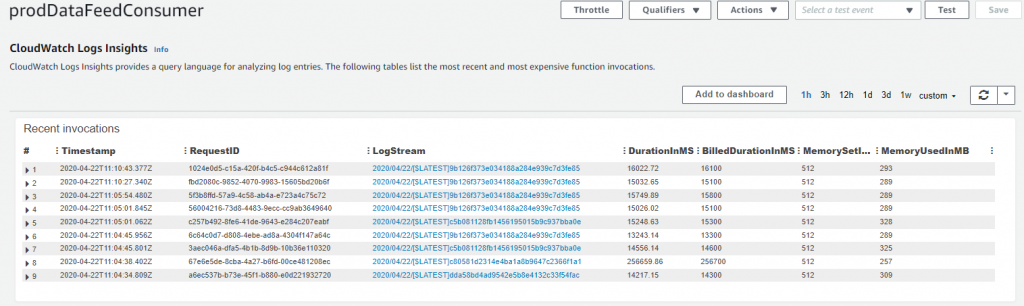
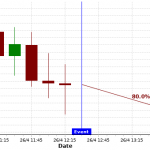
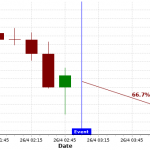
- Invocation duration – we have implemented a 45-second wait on the consumer to allow the redis client to perform an orderly shutdown of the connection to the server. This is a bit excessive. Here’s an AWS X-Ray trace showing the excessive time taken to shut down the connection:

We can also reduce the concurrent latch timeout settings for the Lambda to affect the invocation duration. These settings are used to wait for a large number of candles to be persisted to the database and are really only used for loading historical candle data. Typically, during real-time loads, each stream payload only includes the 15-minute candle to be persisted and, as can be seen in the X-Ray trace above, is completed in less than one second.
So, we should provision around the actual runtime characteristics of the Lambda. Here’s the cost calculation for the new configuration:
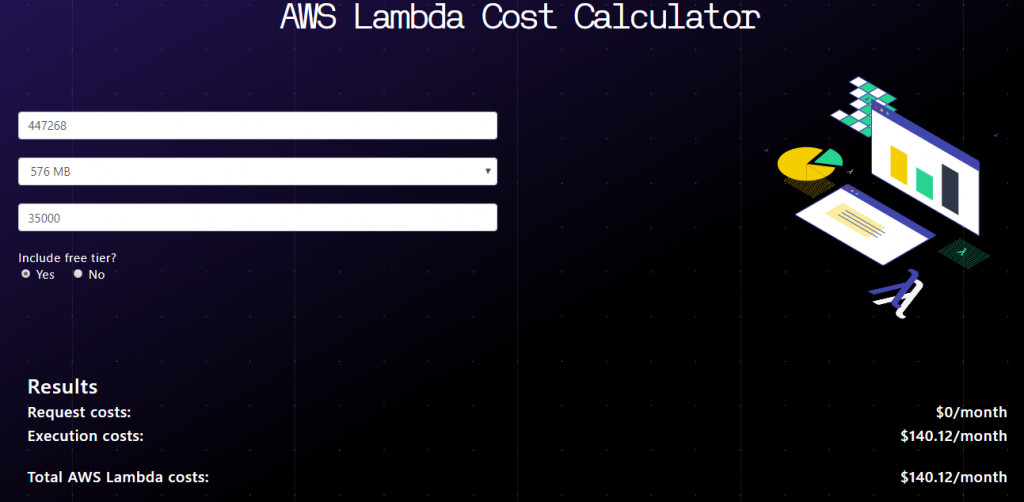
So, it looks like we can reduce our costs from around $980/ month to around $140/ month by provisioning the Lambda with reasonable bounds.
A recalculation of 6445 instruments every 15 minutes for the new projected cost per day of $6.47:
$6.47 / ((6445 candles) * (4 * 24 hours))
= $6.47 / 618 720 candles per day
= $0.0000105 / candle per day
What’s in the pipeline?
We’re looking into reducing the daily costs around the transport layer by replacing the Kinesis streams with alternative technology.
We are currently investigating the use of MongoDB Change Streams as an alternative to Kinesis. So far it looks promising and should reduce costs significantly as we can use our existing MongoDB instances to stream the candle data.
A microservice ‘stream-service’ has been developed and deployed on AWS ECS (Elastic Container Service) using Spring Boot and Docker Container technologies. This service uses a non-blocking reactive connection to MongDB and reads documents as they are inserted into the designated price data collection.
I am also proposing that we replace the current consumer Lambda with a consumer microservice running on AWS ECS. Although the consumer does not really conform to any accepted microservice design standard and is really monolithic in nature, a container-based run-time implementation that can be run transiently seems best suited for this service.
The main reasons for the proposal for an ECS-based consumer are:
- Restriction on triggers for the AWS Lambdas – we had to resort to using the AWS API Gateway as a trigger for the consumer Lambda in order to receive the pricing data payload from the ECS-based stream-service. The API G/W has a default, max timeout setting of 29 seconds that will become an issue when ingesting historical data that typically takes a few minutes to persist to the Postgres database from the consumer.
- Taking advantage of concurrency for faster throughput – AWS Lambdas have a largely undocumented “feature” whereby threads spawned inside the handler are suspended during execution as discussed here: https://dzone.com/articles/multi-threaded-programming-with-aws-lambda. I suspect this may be the cause of some candles being persisted up to 6 minutes late with no failure being reported in the Lambda.